Hadoop 安装搭建伪分布式教程(全面)吐血整理
- 1、安装下载虚拟机 VMware
- 2、下载 Ubuntu18.04 镜像文件,并在 VMware 中添加虚拟机。
- 3、Hadoop 伪分布式搭建
1、安装下载虚拟机 VMware
博主使用的是 VMware Workstation 16 Pro,这个的安装教程很多,大家可以自行搜索安装。
官网:https://www.vmware.com/cn/products/workstation-pro.html
2、下载 Ubuntu18.04 镜像文件,并在 VMware 中添加虚拟机。
Ubuntu 一般使用 18 或者 16 版本,20 版本有些未知的问题。
打开 ubuntu18.04.1 的下载地址:https://www.ubuntu.com/download/desktop,进入页面后点击右边的 Download 按钮开始下载。
- 右上角点击新建虚拟机

- 默认

- 选择自己安装镜像文件的位置

- 这里自己设置账户和密码

- 选择虚拟机的位置,博主放在了 D 盘

- 这个的配置比较高了,也可以使用默认的 4 核

- 按照建议内存,之后就一直下一步

- 这里的磁盘大小默认为 20G,根据自己需要选择大小。将虚拟磁盘储存为单个文件
然后一直下一步,就能等它跑进度条了。
3、Hadoop 伪分布式搭建
前两个都是开胃小菜,这才是正题。
3.1 创建 hadoop 用户,并更新 ubuntu 系统中相应软件,安装 vim 编辑器
3.1.1 创建 hadoop 账户
- 按 Ctrl + Alt + T,即可进入命令行模式。
- 输入以下语句,创建一个名为 hadoop 的用户,useradd 命令的 - m 用来指定用户名,-s 用来指定用户登录时所需的 shell 文件:
sudo useradd -m hadoop -s /bin/bash
- 由于部门权限规定或安全限制,负责部署 hadoop 的管理员没有 linux root 权限,但按照最佳做法,安装时有一些操作需要以 root 用户身份执行。以下给予该用户 root 权限:
sudo adduser hadoop sudo
如果在安装 Ubuntu 时用户名使用的是 hadoop,这两步不需要。
3.1.2 更新命令
- 由于 ubuntu 系统刚完成安装,需要更新相关一些软件,确保接下来的操作可以正常完成:
sudo apt-get update
如果这条命令执行速度很慢,请使用下面的方法(虽然一般很快)
参考 https://blog.csdn.net/m0_37601622/article/details/82968780
如果发现更新速度过慢,或者更新时反复跳出连接超时的提示,则可以将源文件链接地址替换为国内镜像文件从而提高更新速度。首先先利用 cp 命令备份当前系统的源文件,其中第一个参数时拷贝的文件路径和文件名称, 第二个是拷贝到的文件路径和文件名:
sudo cp /etc/apt/sources.list /etc/apt/sources.bak1
打开需要更新的源文件:
sudo gedit /etc/apt/sources.list
将文件内的内容替换成其他源文件:
如清华源:参考 https://mirrors.tuna.tsinghua.edu.cn/help/ubuntu/
完成后保存,重新运行更新命令:
sudo apt-get update
sudo apt-get upgrade
- 上述更新完成后:
部分 linux 系统会自带 vim 编辑器,但若在终端无法启动该编辑器,则需要安装以待后续编辑配置文件,接下来跳出的提示回复 Y 即可:
sudo apt-get install vim
3.2 配置 SSH,并设置无密码登录
3.2.1 下载 SSH
根据 Hadoop 分布式系统的特性,在任务计划分发、心跳监测、任务管理、多租户管理等功能上,需要通过 SSH(Secure Shell) 进行通讯,所以必须安装配置 SSH。另因为 Hadoop 没有提供 SSH 输入密码登录的形式,因此需要将所有机器配置为 NameNode 可以无密码登录的状态。
- 首先安装 SSH server(之所以不需要安装 SSH client 是因为 ubuntu 已经默认安装了):
sudo apt-get install openssh-server
- 完成后连接本地 SSH
ssh localhost
按提示输入 yes,再输入 hadoop 用户的密码,完成登录。
3.2.2 设置无密码登录
- 以下进行无密码登录的设置,首先先退出刚刚 ssh localhost 的连接:
exit
- 然后进入 SSH 对应目录下,该目录包含了几乎所有当前用户 SSH 配置认证相关的文件:
cd ~/.ssh/
- 输入生成 SSH 私钥与公钥的命令,-t 用于声明密钥的加密类型,输入 Hadoop 密码。这一步会提醒设置 SSH 密码,输入密码时直接回车就表示无密码,第二次输入密码回车确定,最后一次提交:
ssh-keygen -t rsa
- 将生成的 SSH 的公钥加入目标机器的 SSH 目录下,这里采用 cat 命令与 >>,cat file1>>file2 的含义为将 file1 内容 append 到 file2 中。
cat ./id_rsa.pub >> ./authorized_keys
3.3 安装 Java 并配置环境变量
3.3.1 下载 Java
Hadoop 和与之相关的很多工具都是通过 java 语言编写的,并且很多基于 hadoop 的应用开发也是使用 java 语言的,但是 ubuntu 系统不会默认安装 java 环境,所以需要安装 java 并配置环境变量。以下安装下载 java 的 jdk、jre:
sudo apt-get install default-jre default-jdk
3.3.2 配置环境变量
- 通过 vim 编辑器打开环境变量的设置文件:
sudo vim ~/.bashrc
- 在文件的尾部加上以下语句:
export JAVA_HOME=/usr/lib/jvm/default-java
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
在这一步在我的虚拟机中直接复制时会出现第一句的 export 只剩 rt 两个字母,必须要手动输入 export。
3. 按 Esc 键退出,然后输入: wq 保存修改。然后使环境变量生效:
source ~/.bashrc
3.4 下载编译好的 hadoop,配置 hadoop 的环境
3.4.1 下载并解压
- 在虚拟机内的火狐浏览器中输入 https://archive.apache.org/dist/hadoop/common/hadoop-2.9.2/,下载 hadoop 应用,默认保存至 downloads 文件夹下。选择已编译好的版本 hadoop-2.9.2.tar.gz,因为该版本可以直接解压使用,更为方便。
- 进入解压包存放的 Downloads 文件夹,右键属性查看压缩包的绝对路径,然后解压至 / usr/local 目录下:
sudo tar -zxf /home/hadoop/Downloads/hadoop-2.9.2.tar.gz -C /usr/local
- 进入刚刚解压后存放的目录下:
cd /usr/local/
- 将该文件夹的名字重命名为 hadoop,屏蔽掉版本号的信息,使得后续命令行输入更为简便:
sudo mv ./hadoop-2.9.2/ ./hadoop
3.4.2 配置环境
- 将已重命名的该文件夹的拥有者,指定给用户 hadoop,缺少这一步,将导致后续操作特别是运行 Hadoop 时,反复因权限不足而停止:
sudo chown -R hadoop ./hadoop
- 经后续测试发现问题,虽然已经为 ubuntu 系统设置了 java 的环境变量,但 hadoop 实际运行时仍会出现找不到 java-jdk 的现象,故再对 hadoop 的环境文件进行修改,此外,该文件还包括启动参数、日志、pid 文件目录等信息。先进入目录:
cd ./hadoop/etc/hadoop
- 使用 vim 编辑器,打开环境变量文件:
sudo vim hadoop-env.sh
- 添加该语句(这里也需要手动输入 export):
export JAVA_HOME=/usr/lib/jvm/default-java
- 按 Esc 键退出,然后输入: wq 保存修改。然后使环境变量生效:
source hadoop-env.sh
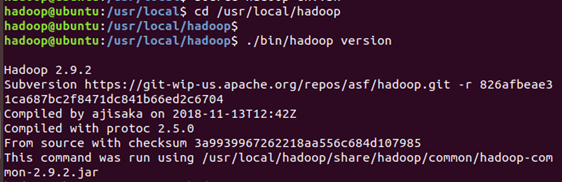
- 截至目前,hadoop 框架已经搭建好了,可以通过调用版本号进行测试 hadoop 是否可用
cd /usr/local/hadoop
./bin/hadoop version
正确搭建应该能看到 hadoop 的版本号等信息:
3.5 配置四个文件
从字面上,很好理解伪分布式的含义,对于 Hadoop 而言,可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode。设置 Hadoop 参数的主要方式是配置一系列由 Hadoop 守护进程和客户端读取的配置文件,如之前提及的 hadoop-env.sh,还包括 core-site.xml、hdfs-site.xml、mapred-site.xml、log4j.properties、taskcontroller.cfg 等,伪分布式需要修改四个文件,修改的顺序没有特殊要求,以下进行逐一介绍。
此时需要在 hadoop 文件夹下的 hadoop 文件中
绝对路径是 cd /usr/local/hadoop/etc/hadoop
3.5.1 core-site.xml
- 先打开 xml 文件,注意./ 表示当前文件夹下,当前应该在第二个 hadoop 文件夹下
cd ./etc/hadoop/。
sudo gedit core-site.xml
- 打开 xml 文件应该是有内容的,如果没有内容说明打开文件不对,需要检查输入的路径及文件名是否正确。将替换为以下内容,第一个属性表示 Hadoop 重要临时文件的存放目录,指定后需将使用到的所有子级文件夹都要手动创建出来,否则无法正常启动服务;第二个被官方称之为默认系统文件的名称(the name of the default file system),实际上决定了文件系统的主机号、端口号,对于伪分布式模型来说,其主机地址为 localhost。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
3.5.2 hdfs-site.xml
- 同样进入 hdfs-site.xml 文件:
sudo gedit hdfs-site.xml
- 对 hdfs-site.xml 进行同样的替换操作,属性的含义分别为复制的块的数量、DFS 管理节点的本地存储路径、DFS 数据节点的本地存储路径:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
3.5.3 mapred-site.xml
1.Hadoop2.X 并没有像 1.X 提供 mapred-site.xml 文件,需要将样本文件复制为可使用的配置文件:
mv mapred-site.xml.template mapred-site.xml
- 同样打开
sudo gedit mapred-site.xml
- 这里使用 yarn。yarn 是一种资源管理和作业调度技术,作为 Hadoop 的核心组件之一,负责将系统资源分配给在 Hadoop 集群中运行的各种应用程序,并调度要在不同集群节点上执行的任务,其基本思想是将资源管理和作业调度 / 监视的功能分解为单独的 daemon,总体上 yarn 是 master/slave 结构,在整个资源管理框架中,ResourceManager 为 master,NodeManager 是 slaver。具体配置内容如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.5.4 yarn-site.xml
- 打开
sudo gedit yarn -site.xml
- 然后配置 yarn-site.xml 文件,这里修改 NodeManager 上运行的附属服务即可:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3.6 格式化后启动、调用实例、停止所有运行的 hadoop 进程
3.6.1 格式化并启动
- 为了保险起见,执行这一步前关闭命令行模式,重新打开,放弃当前路径。
更改配置并保存后,格式化 HDFS 的 NameNode,在这一步之前,如果 hdfs-site.xml 中 dfs.namenode.name.dir 属性指定的目录不存在,格式化命令会自动创建之;如果存在,请确保其权限设置正确,此时格式操作会清除其内部所有的数据并重新建立一个新的文件系统:
/usr/local/hadoop/bin/hdfs namenode -format
显示信息内若包含以下内容,则说明成功格式化:

- 然后启动全部进程:
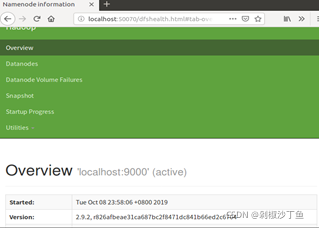
start-all.sh
- 成功启动后,可以通过 web 浏览器访问 http://localhost:50070,可以看到如下界面:
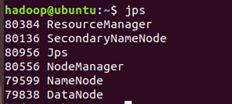
- 输入 jps 查看到六个进程,如果缺少某进程需要查询解决方法:
- 在 HDFS 中创建用户目录:
hdfs dfs -mkdir -p /user/hadoop
- 创建 input 目录,用于输入数据:
hdfs dfs -mkdir input
- 将所需的 xml 配置文件复制到 input 中:
(需要注意路径)
hdfs dfs -put usr/local/hadoop/etc/hadoop/*.xml input
- 如果系统之前运行过 hadoop,则需要删除 output 目录:
hdfs dfs -rm -r output
这几步会出现很多的 warning,不用在意。
3.6.2 调用实例
- 运行实例,需要先进入 hadoop 的文件夹下
cd /usr/local/hadoop
- 输入
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar wordcount input output
要等一会,结果如下图
- 然后进入 hadoop 下面的 bin
cd /usr/local/hadoop/bin
- 查看运行结果
hdfs dfs –ls ./output
hdfs dfs -cat output/*
到这里,整个安装过程就结束了。第一次这么认真写 CSDN,完全是因为装这个伪分布式实在太痛苦了。会遇到很多没法解决的问题,我基本重装了虚拟机 6 遍,整个花时间十几个小时,吐血。