文章目录
一、RPC 是什么
RPC 是指远程过程调用,也就是说两台服务器 A,B,一个应用部署在 A 服务器上,想要调用 B 服务器上应用提供的函数 / 方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。
二、RPC 需要解决的问题
1、Call ID 映射
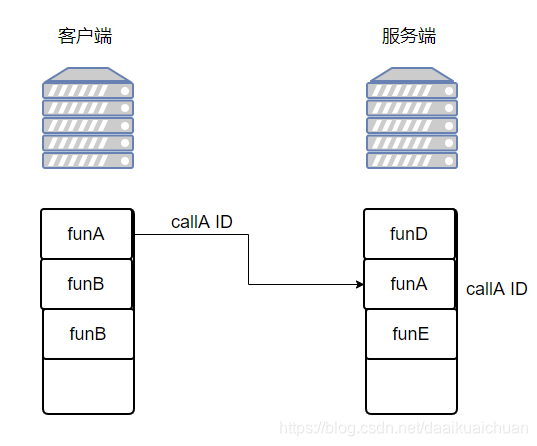
我们怎么告诉远程机器我们要调用 funA,而不是 funB 或者 funC 呢?在本地调用中,函数体是直接通过函数指针来指定的,我们调用 funA,编译器就自动帮我们调用它相应的函数指针。但是在远程调用中,函数指针是不行的,因为两个进程的地址空间是完全不一样的。
所以,在 RPC 中,所有的函数都必须有自己的一个 ID。这个 ID 在所有进程中都是唯一确定的。客户端在做远程过程调用时,必须附上这个 ID。然后我们还需要在客户端和服务端分别维护一个 {函数 <–> Call ID} 的对应表。两者的表不一定需要完全相同,但相同的函数对应的 Call ID 必须相同。
【Note】当客户端需要进行远程调用时,它就查一下这个表,找出相应的 Call ID,然后把它传给服务端,服务端也通过查表,来确定客户端需要调用的函数,然后执行相应函数的代码。
2、序列化和反序列化
客户端怎么把参数值传给远程的函数呢?在本地调用中,我们只需要把参数压到栈里,然后让函数自己去栈里读就行。
但是在远程过程调用时,客户端跟服务端是不同的进程,不能通过内存来传递参数。甚至有时候客户端和服务端使用的都不是同一种语言(比如服务端用 C++,客户端用 Java 或者 Python)。
【Note】这时候就需要客户端把参数先转成一个字节流(编码),传给服务端后,再把字节流转成自己能读取的格式(解码)。这个过程叫序列化和反序列化。同理,从服务端返回的值也需要序列化反序列化的过程。
为什么需要序列化?
-
转换为字节流方便进行网络传输。
-
实现跨平台、跨语言;如果是跨平台的序列化,则发送方序列化后,接收方可以用任何其支持的平台反序列化成相应的版本,比如 Java 序列化后, 用. net、phython 等反序列化。
3、网络传输
远程调用往往用在网络上,客户端和服务端是通过网络连接的。所有的数据都需要通过网络传输,因此就需要有一个网络传输层。
**【Note】网络传输层需要把 Call ID 和序列化后的参数字节流传给服务端,然后再把序列化后的调用结果传回客户端。**只要能完成这两者的,都可以作为传输层使用。因此,它所使用的协议其实是不限的,能完成传输就行。尽管大部分 RPC 框架都使用 TCP 协议,但其实 UDP 也可以,而 gRPC 干脆就用了 HTTP2。
所以,要实现一个 RPC 框架,其实只需要把以上三点实现了就基本完成了。Call ID 映射可以直接使用函数字符串,也可以使用整数 ID。映射表一般就是一个哈希表。序列化反序列化可以自己写,也可以使用 Protobuf 或者 FlatBuffers 之类的。网络传输库可以自己写 socket,或者用 asio,ZeroMQ,Netty 之类。
4、RPC 的调用流程图

三、常用的 RPC 框架
-
gRPC 是 Google 公布的开源软件,基于最新的 HTTP2.0 协议,并支持常见的众多编程语言。 我们知道 HTTP2.0 是基于二进制的 HTTP 协议升级版本,目前各大浏览器都在快马加鞭的加以支持。 这个 RPC 框架是基于 HTTP 协议实现的,底层使用到了 Netty 框架的支持。
-
Thrift 是 Facebook 的一个开源项目,主要是一个跨语言的服务开发框架。它有一个代码生成器来对它所定义的 IDL 定义文件自动生成服务代码框架。用户只要在其之前进行二次开发就行,对于底层的 RPC 通讯等都是透明的。不过这个对于用户来说的话需要学习特定领域语言这个特性,还是有一定成本的。
-
Dubbo 是阿里集团开源的一个极为出名的 RPC 框架,在很多互联网公司和企业应用中广泛使用。协议和序列化框架都可以插拔是及其鲜明的特色。同样的远程接口是基于 Java Interface,并且依托于 spring 框架方便开发。可以方便的打包成单一文件,独立进程运行,和现在的微服务概念一致。