文章目录
一、为什么要采用分库分表
我们公司是做车联网项目的,其中车辆的定位啊、报警数据非常的多,
其中任意一项一个月就会有千万条数据,这个时候呢,
单是一个月的数据已是非常之庞大,查询效率已是非常缓慢,
如果不采用分表,那么半年后,一年后,表中数据不可想象..............
简单来说,就是数据库中的数据量猛增,访问性能也变慢,优化迫在眉睫。
我们这个时候就会分析,问题究竟出现在哪?
关系型数据库本身比较容易成为系统瓶颈,单机存储容量、连接数、处理能力都有限。当单表的数据量达到 1000W 或 100G 以后,由于查询维度较多,即使添加从库、优化索引,做很多操作时性能仍下降严重。
解决方案:
-
如果是硬件问题导致(存储容量、CPU),则提升服务器硬件水平
-
如果是 Mysql 本身原因导致(数据量过多),则可以根据业务划分不同数据库,把数据分散在不同的数据库中,使得单一数据库的数据量变小来缓解单一数据库的性能问题
分库分表的核心作用:
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成 ,将数据大表拆分成若干数据小表,使得单一数据库、单一数据表的数据量变小,从而提升数据库性能。
最终,我们决定采用,使用sharding-jdbc, 来对我们的项目进行分库分表,至于为什么要是用sharding-jdbc因为其使用简单,兼容各种 orm(我们项目才用的 mp), 而且非常轻量级,代码侵入小,详情请看下边介绍!
二、Sharding-JDBC 介绍
来源与特性
Sharding-JDBC是当当网研发的开源分布式数据库中间件,
从 3.0 开始Sharding-JDBC被包含在 Sharding-Sphere 中,
之后该项目进入进入Apache孵化器,4.0版本之后的版本为Apache版本。 ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,
它由Sharding-JDBC、ShardingProxy和Sharding-Sidecar(计划中)这3款相
互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和
数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
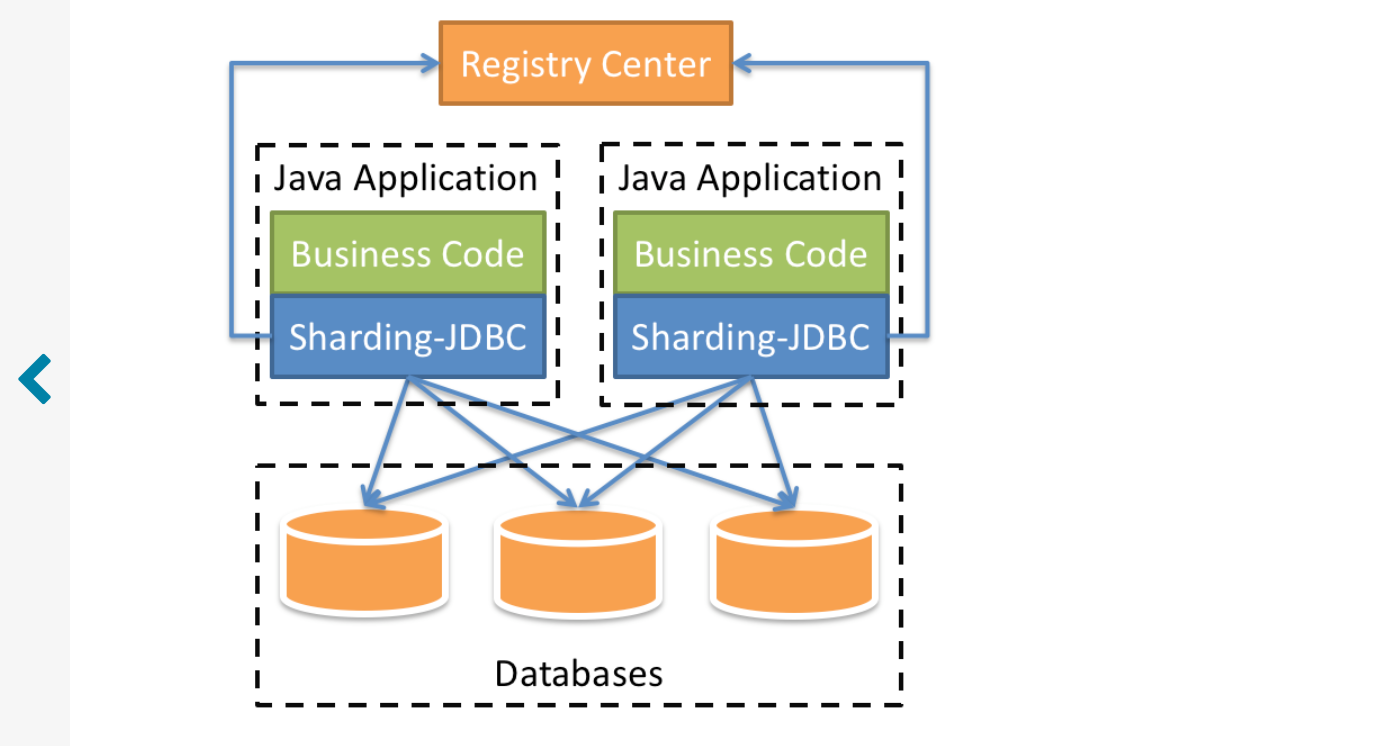
Sharding-JDBC,它定位为轻量级Java框架,在Java的JDBC层提供的额外服务。
它使用客户端 直连数据库,以jar包形式提供服务,无需额外部署和依赖,
可理解为增强版的JDBC驱动,完全兼容JDBC和各种 ORM框架。
Sharding-JDBC的核心功能为数据分片和读写分离,通过Sharding-JDBC,
应用可以透明的使用jdbc访问已经分库
分表、读写分离的多个数据源,而不用关心数据源的数量以及数据如何分布。
官方地址:https://shardingsphere.apache.org/document/current/cn/overview/
逻辑表
水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为 10 张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order。
真实表
在分片的数据库中真实存在的物理表。即上个示例中的t_order_0到t_order_9。
数据节点
数据分片的最小单元。由数据源名称和数据表组成,例:ds_0.t_order_0。
分片键
用于分片的数据库字段,是将数据库 (表) 水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL 中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere 也支持根据多个字段进行分片。
分片算法
通过分片算法将数据分片,支持通过=、>=、<=、>、<、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供 4 种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
- 精确分片算法
对应 PreciseShardingAlgorithm,用于处理使用单一键作为分片键的 = 与 IN 进行分片的场景。需要配合 StandardShardingStrategy 使用。
- 范围分片算法
对应 RangeShardingAlgorithm,用于处理使用单一键作为分片键的 BETWEEN AND、>、<、>=、⇐ 进行分片的场景。需要配合 StandardShardingStrategy 使用。
- 复合分片算法
对应 ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合 ComplexShardingStrategy 使用。
- Hint 分片算法
对应 HintShardingAlgorithm,用于处理使用 Hint 行分片的场景。需要配合 HintShardingStrategy 使用。
分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供 5 种分片策略。
- 标准分片策略
对应 StandardShardingStrategy。提供对 SQL 语句中的 =, >, <,>=, ⇐, IN 和 BETWEEN AND 的分片操作支持。StandardShardingStrategy 只支持单分片键,提供 PreciseShardingAlgorithm 和 RangeShardingAlgorithm 两个分片算法。PreciseShardingAlgorithm 是必选的,用于处理 = 和 IN 的分片。RangeShardingAlgorithm 是可选的,用于处理 BETWEEN AND, >, <, >=, ⇐ 分片,如果不配置 RangeShardingAlgorithm,SQL 中的 BETWEEN AND 将按照全库路由处理。
- 复合分片策略
对应 ComplexShardingStrategy。复合分片策略。提供对 SQL 语句中的 =, >, <,>=, ⇐, IN 和 BETWEEN AND 的分片操作支持。ComplexShardingStrategy 支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
- 行表达式分片策略
对应 InlineShardingStrategy。使用 Groovy 的表达式,提供对 SQL 语句中的 = 和 IN 的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的 Java 代码开发,如: t_user_$->{u_id % 8} 表示 t_user 表根据 u_id 模 8,而分成 8 张表,表名称为t_user_0到t_user_7。
- Hint 分片策略
对应 HintShardingStrategy。通过 Hint 指定分片值而非从 SQL 中提取分片值的方式进行分片的策略。
- 不分片策略
对应 NoneShardingStrategy。不分片的策略。
分片策略配置
对于分片策略存有数据源分片策略和表分片策略两种维度。
- 数据源分片策略(根据什么规则进行分库)
对应于 DatabaseShardingStrategy。用于配置数据被分配的目标数据源。
- 表分片策略(根据什么规则进行分表)
对应于 TableShardingStrategy。用于配置数据被分配的目标表,该目标表存在与该数据的目标数据源内。故表分片策略是依赖与数据源分片策略的结果的。
两种策略的 API 完全相同。
自增主键生成策略
通过在客户端生成自增主键替换以数据库原生自增主键的方式,做到分布式主键无重复。
逻辑表与物理表联系
这个逻辑表与真实表有什么联系或者怎么理解呢?比如说,我原来只有一张表t_order我只需要精准的指向这个表进行操作即可,现在分表后有了t_order_0到t_order_9这十张表,那么我在代码中要自己精确指定操作到某张表吗?当然不是,我们仍像原来一样,只需要定义好表的分片策略后,以及定位好t_order_0到t_order_9这十张表的逻辑表名为t_order后,我们自己在代码中仍像原来一样操作t_order,sharding-jdbc就会根据策略选择到具体的表(更改 sql 找到对应库与表)进行操作!
三、Sharding-JDBC 的实际运用
本次演示采用 springboot版本:2.2.5.RELEASE、sharding-jdbc版本:sharding-jdbc-spring-boot-starter:4.0.0-RC1
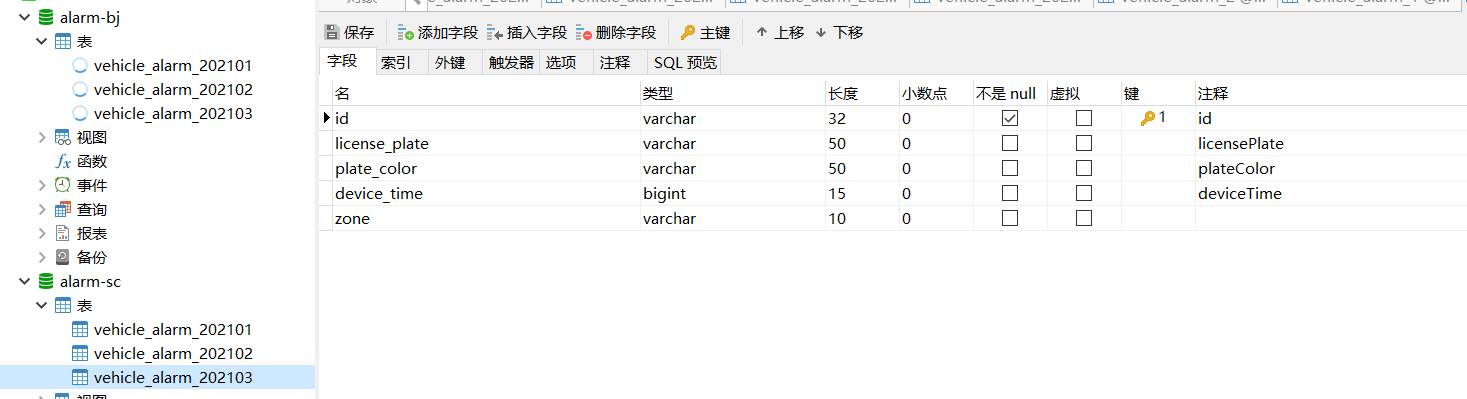
(1)数据库与表准备
(2)项目核心依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
<scope>runtime</scope>
</dependency>
<!--sharding jdbc springboot-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
(3)sharding-jdbc 的配置
(1)配置
server:
port: 8080
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 打印sql
props:
sql:
show: true
# 数据源配置
datasource:
# names必须对应数据库的名字,且与下方配置相对应
names: alarm-sc,alarm-bj
alarm-sc:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://xxxx:3306/alarm-sc?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: root
alarm-bj:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://xxx:3306/alarm-bj?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: root
sharding:
# 默认数据库策略 如果不想分库,可不设此配置
defaultDatabaseStrategy:
# 分库
standard:
# 分片键 zone 表示根据 数据zone这一列的值与自定义的算法进行分片
shardingColumn: zone
# 精准分片算法
preciseAlgorithmClassName: com.leilei.algorithm.SubDataBasePreciseAlgorithm
# 范围分片算法
rangeAlgorithmClassName: com.leilei.algorithm.SubDataBaseRangeAlgorithm
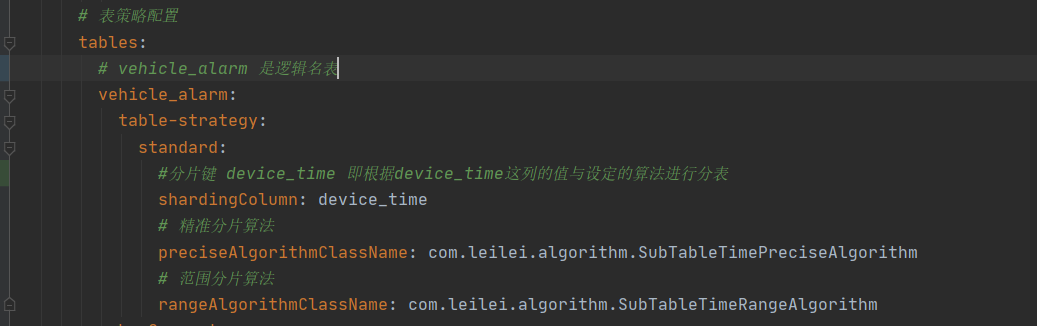
# 表策略配置
tables:
# vehicle_alarm 是逻辑名表
vehicle_alarm:
table-strategy:
standard:
#分片键 device_time 即根据device_time这列的值与设定的算法进行分表
shardingColumn: device_time
# 精准分片算法
preciseAlgorithmClassName: com.leilei.algorithm.SubTableTimePreciseAlgorithm
# 范围分片算法
rangeAlgorithmClassName: com.leilei.algorithm.SubTableTimeRangeAlgorithm
keyGenerator:
# 唯一值生成类型为雪花算法
type: SNOWFLAKE
# 对id列采用 sharding-jdbc的全局id生成策略
column: id
# mybatis-plus相关配置
mybatis-plus:
type-aliases-package: com.leilei.entity
global-config:
db-config:
id-type: auto
table-underline: true
logic-not-delete-value: 0
logic-delete-value: 1
configuration:
cache-enabled: false
map-underscore-to-camel-case: true
您也可以选择简单的配置
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 打印sql
props:
sql:
show: true
# 数据源配置
datasource:
names: sc
sc:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://xxx:3306/alarm_sc?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: root
sharding:
# 表策略配置
tables:
# vehicle_alarm 是逻辑表
vehicle_alarm:
# 分表节点 可以理解为分表后的那些表 比如 vehicle_alarm_1 ,vehicle_alarm_2
actualDataNodes: sc.vehicle_alarm_$->{1..2}
tableStrategy:
inline:
# 根据哪列分表
shardingColumn: id
# 分表算法 例如:Id为奇数 则为vehicle_alarm_2 id为偶数 vehicle_alarm_1
algorithmExpression: vehicle_alarm_$->{id % 2 + 1}
# 分表后,sharding-jdbc的全局id生成策略
keyGenerator:
type: SNOWFLAKE
# 对id列采用 sharding-jdbc的全局id生成策略
column: id
(2)配置解读
分库 ,数据源配置(本示例中使用了两个库,alarm-sc,alarm-bj)
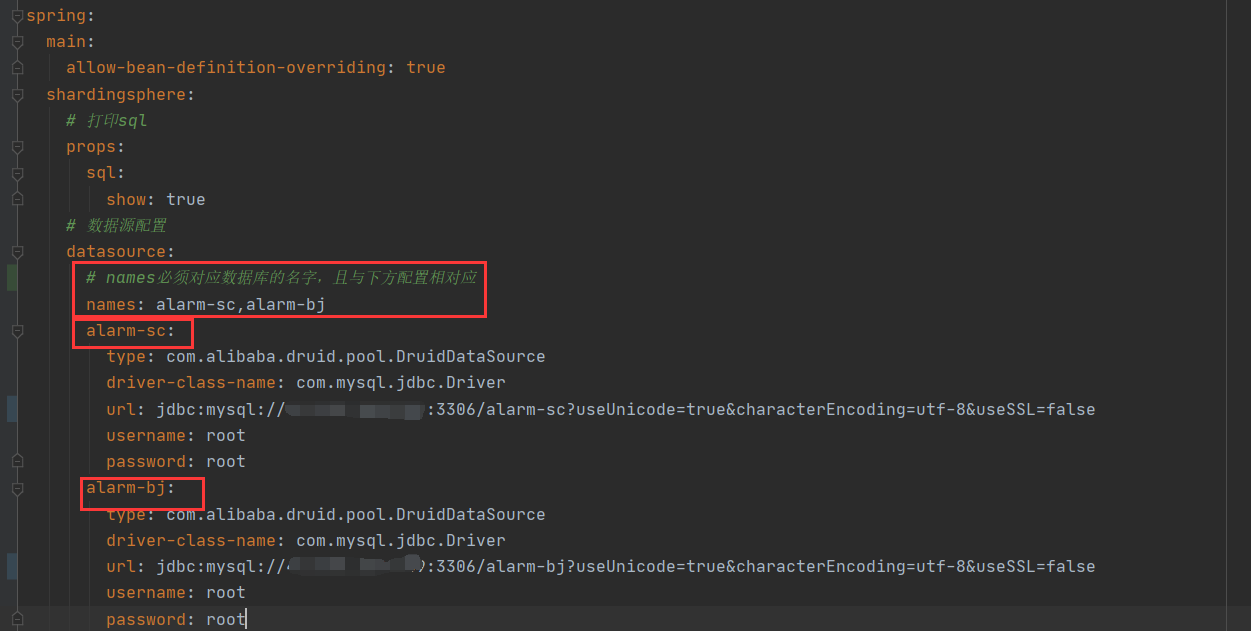
分库核心配置
配置中指明了分片键为zone,表示根据 数据 zone 这一列的值与自定义的算法进行分片
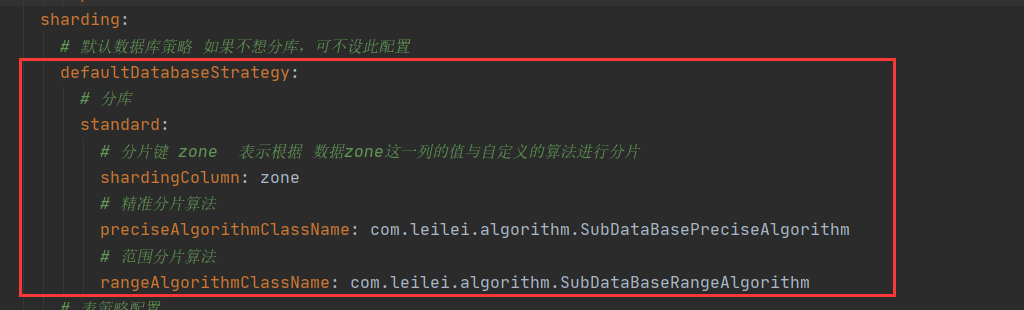
分表核心配置
分片键 device_time 即根据 device_time 这列的值与设定的算法进行分表
整体配置预期效果:

由于分表后,我们就没法再使用自增主键了(因为会出现相同 ID 情况,所以呢,采用了雪花算法生成分布式唯一 ID)

Mybatis-plus 配置这里不做讲解,如对 Mybatis-plus 不熟悉的请看我的 mybatos-plus 相关博客
SpringBoot 整合 Mybatis-plus(一)基本使用与自定义模板代码生成器
SpringBoot 整合 Mybatis-plus(二) 多数据源 Druid 监控, Atomikos 处理事务,跨库连表查询
springboot2.3 整合 mybatis-plus 高级功能
(3)自定义分片算法
① 自定义精准分表算法
package com.leilei.algorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.text.SimpleDateFormat;
import java.util.Collection;
import java.util.Date;
/**
* @author lei
* @version 1.0
* @date 2021/2/28 16:59
* @desc 自定义精准分表算法 (根据时间 按月分表)
*/
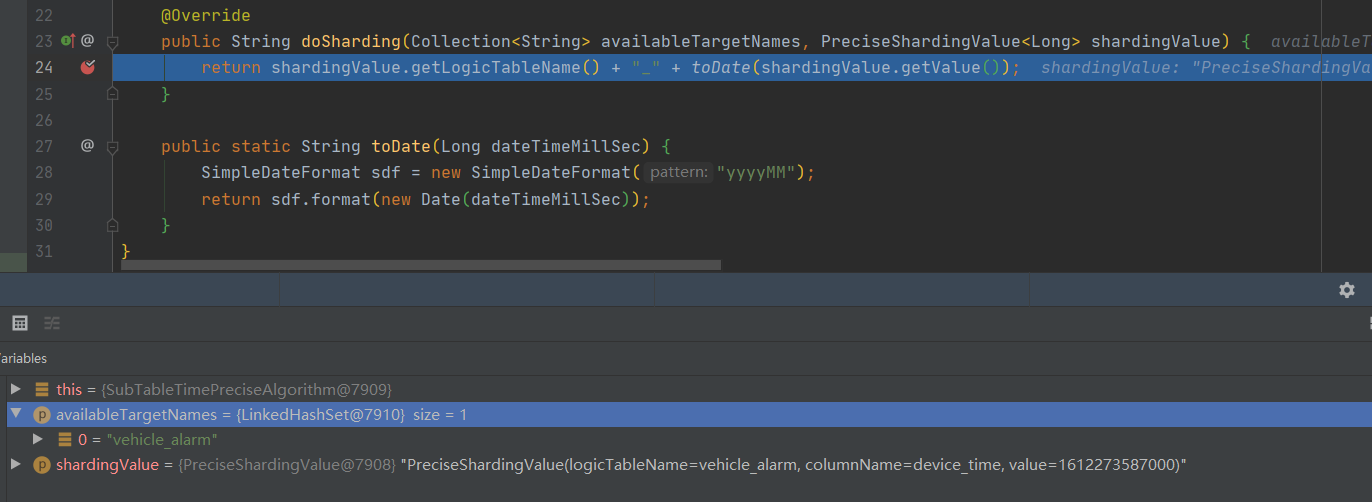
public class SubTableTimePreciseAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
* @param availableTargetNames 所有的分片集 由于我这个算法是指定了分表算法,则这里是逻辑表名列表 目前则为"vehicle_alarm"
* @param shardingValue 分片键(指定的那列作为分片条件)
* @return
*/
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
return shardingValue.getLogicTableName() + "_" + toDate(shardingValue.getValue());
}
public static String toDate(Long dateTimeMillSec) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMM");
return sdf.format(new Date(dateTimeMillSec));
}
}
② 自定义范围分表算法
package com.leilei.algorithm;
import com.google.common.collect.Range;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Collection;
import java.util.Date;
import java.util.LinkedHashSet;
/**
* @author lei
* @version 1.0
* @date 2021/2/28 20:59
* @desc 自定义范围分表算法 (根据时间范围筛选数据表)
*/
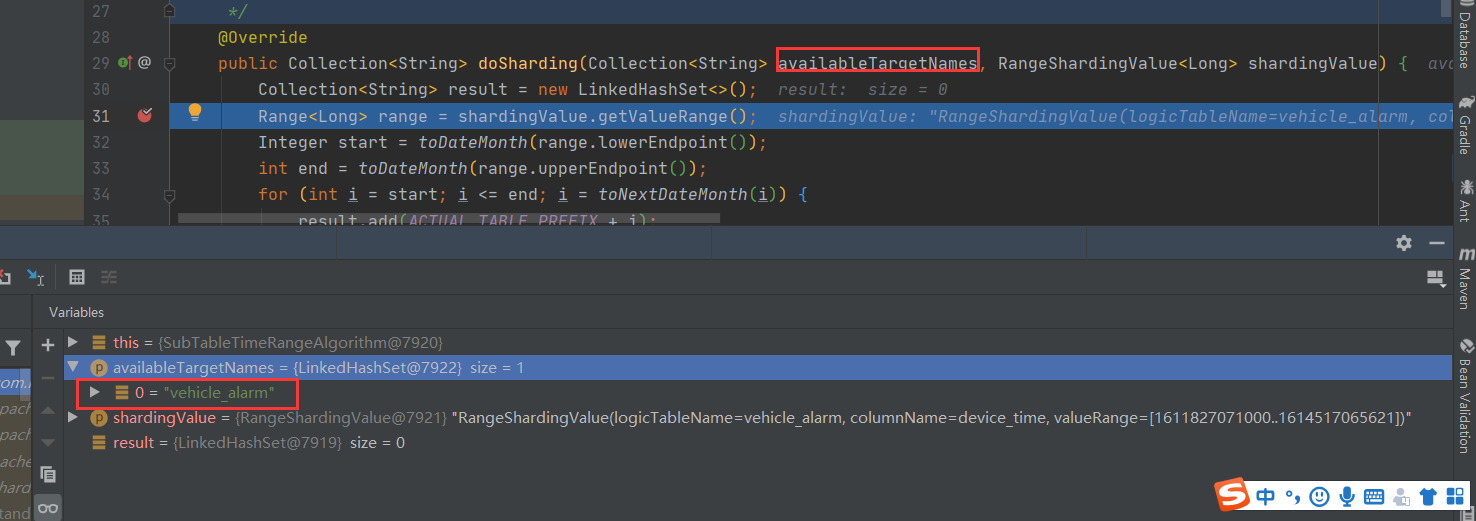
public class SubTableTimeRangeAlgorithm implements RangeShardingAlgorithm<Long> {
private static final String ACTUAL_TABLE_PREFIX = "vehicle_alarm_";
/**
* @param availableTargetNames 所有的分片集 由于我这个算法是指定了分表算法,则这里是逻辑表名列表 目前则为"vehicle_alarm"
* @param shardingValue 分片键(指定的那列作为分片条件)
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> shardingValue) {
Collection<String> result = new LinkedHashSet<>();
Range<Long> range = shardingValue.getValueRange();
Integer start = toDateMonth(range.lowerEndpoint());
int end = toDateMonth(range.upperEndpoint());
for (int i = start; i <= end; i = toNextDateMonth(i)) {
result.add(ACTUAL_TABLE_PREFIX + i);
}
return result;
}
public static Integer toDateMonth(Long dateTimeMillSec) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMM");
return Integer.valueOf(sdf.format(new Date(dateTimeMillSec)));
}
public static Integer toNextDateMonth(Integer dateMonth) {
SimpleDateFormat dft = new SimpleDateFormat("yyyyMM");
try {
Date date = dft.parse(dateMonth.toString());
Calendar cal = Calendar.getInstance();
cal.setTime(new Date(date.getTime()));
cal.add(Calendar.MONTH, 1);
String preMonth = dft.format(cal.getTime());
return Integer.valueOf(preMonth);
} catch (ParseException e) {
e.printStackTrace();
}
return 0;
}
}
③ 自定义精准分库算法
package com.leilei.algorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
import java.util.Objects;
/**
* @author lei
* @version 1.0
* @date 2021/3/2 21:52
* @desc 自定义精准分片策略 根据Zone(数据库)
*/
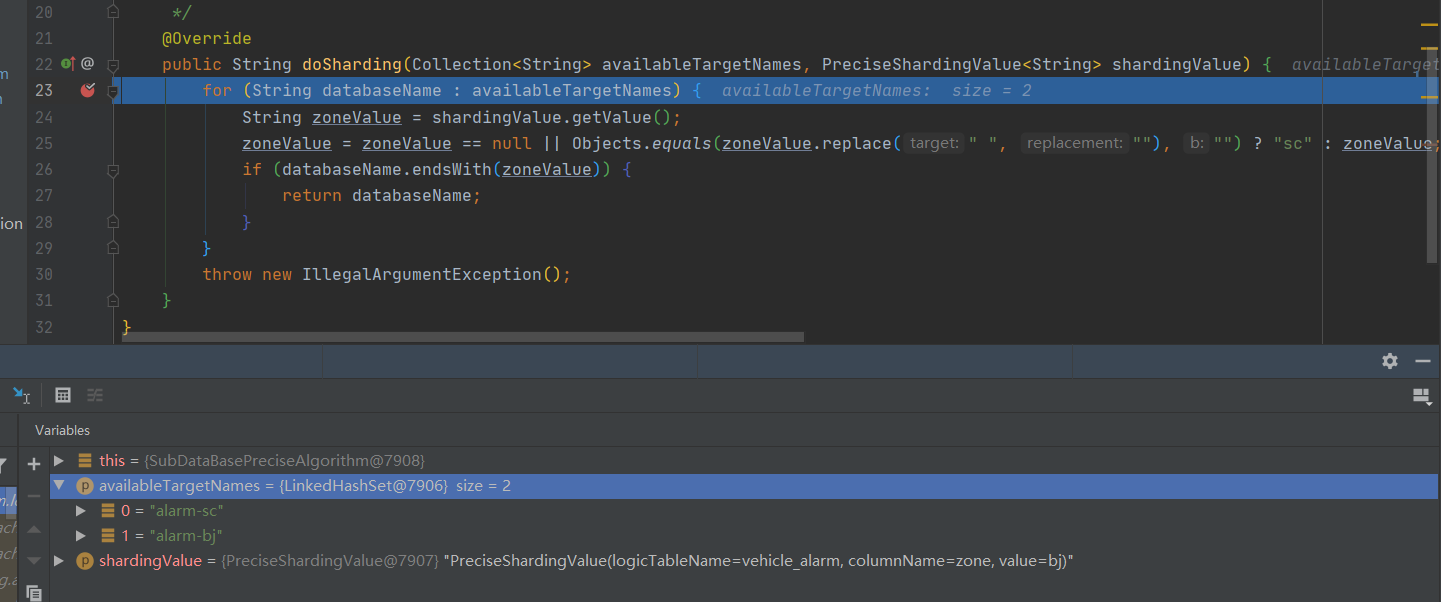
public class SubDataBasePreciseAlgorithm implements PreciseShardingAlgorithm<String> {
/**
* @param availableTargetNames 所有的分片集 由于我这个算法是指定了分表算法,则这里是库列表即names 指定的名字列表
* @param shardingValue 分片键(指定的那列作为分片条件)
* @return
*/
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<String> shardingValue) {
for (String databaseName : availableTargetNames) {
String zoneValue = shardingValue.getValue();
zoneValue = zoneValue == null || Objects.equals(zoneValue.replace(" ", ""), "") ? "sc" : zoneValue;
if (databaseName.endsWith(zoneValue)) {
return databaseName;
}
}
throw new IllegalArgumentException();
}
}
④ 自定义范围分库算法
package com.leilei.algorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.util.Collection;
import java.util.LinkedList;
import java.util.List;
import java.util.stream.Collectors;
/**
* @author lei
* @version 1.0
* @date 2021/3/2 22:10
* @desc 自定义范围分片策略 根据Zone(数据库)
*/
public class SubDataBaseRangeAlgorithm implements RangeShardingAlgorithm<String> {
public static final String DB_PREFIX = "alarm-";
/**
* @param availableTargetNames 所有的分片集 由于我这个算法是指定了分表算法,则这里是库列表即names 指定的名字
* @param shardingValue 分片键(指定的那列作为分片条件)
* @return
* @desc 由于我这里指定的一个业务列作为分库策略 比如zone为(四川 sc,北京 bj,山西 sx等)故此这里采用ThreadLocal 每次有涉及到分库操作时,
* 先将需要查询的库,存入到threadLocal中。详情请查看单元测试
*/
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<String> shardingValue) {
List<String> dbList = DbSelectUtil.DB_SELECTOR.get();
System.out.println(dbList);
Collection<String> finaDbList = new LinkedList<>();
if (dbList.isEmpty()) {
finaDbList.add(DB_PREFIX + "sc");
}else {
finaDbList.addAll(dbList.parallelStream().map(e->DB_PREFIX+e).collect(Collectors.toList()));
}
return finaDbList;
}
}
public class DbSelectUtil {
public static ThreadLocal<List<String>> DB_SELECTOR = new ThreadLocal<>();
}
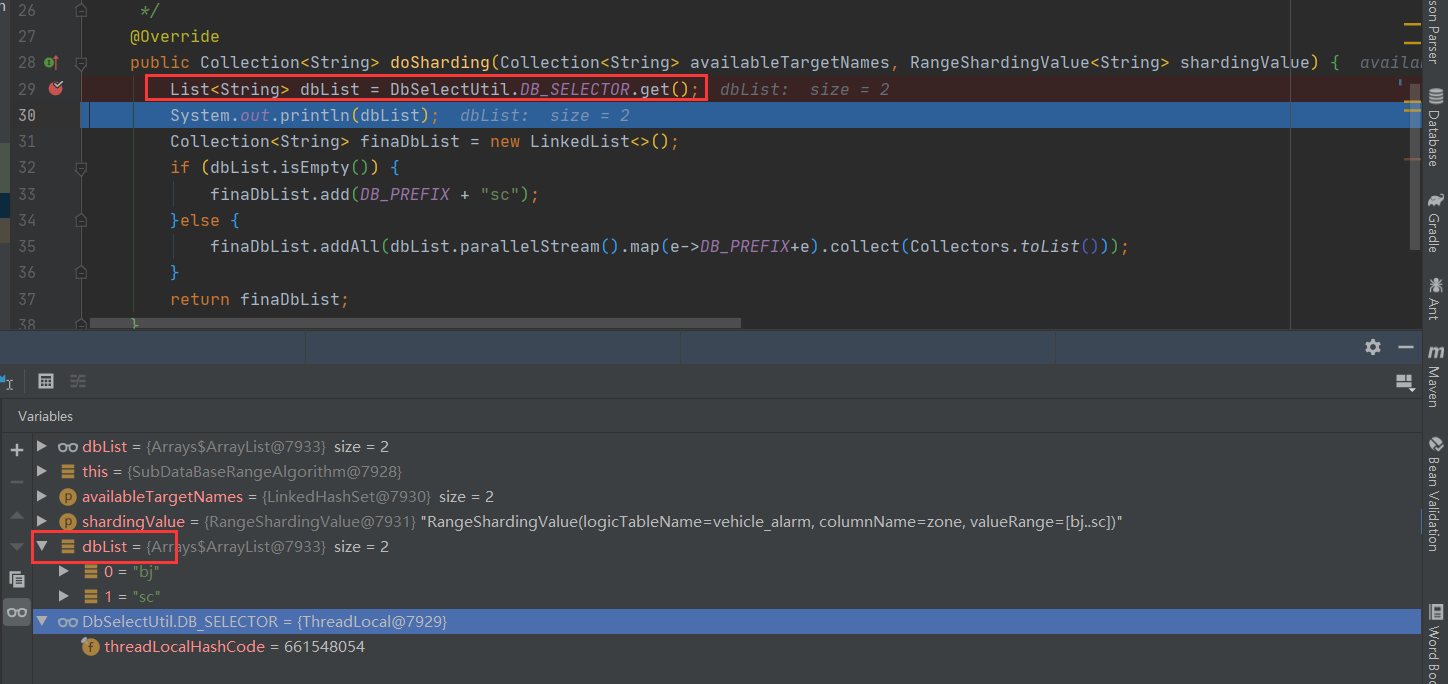
(4)测试
插入数据
@Test
public void testInsertAlarm() {
VehicleAlarm vehicleAlarm = new VehicleAlarm();
long[] timeArr = {1611827071123L, 1612274617000L, 1614693856000L};
for (int i = 1; i < 20; i++) {
vehicleAlarm.setLicensePlate("川E" + System.currentTimeMillis()/123456789);
vehicleAlarm.setPlateColor("黄");
vehicleAlarm.setZone(i % 2 == 0 ? "sc" : "bj");
vehicleAlarm.setDeviceTime(timeArr[(int) (Math.random() * 3)]);
vehicleAlarmMapper.insert(vehicleAlarm);
}
}
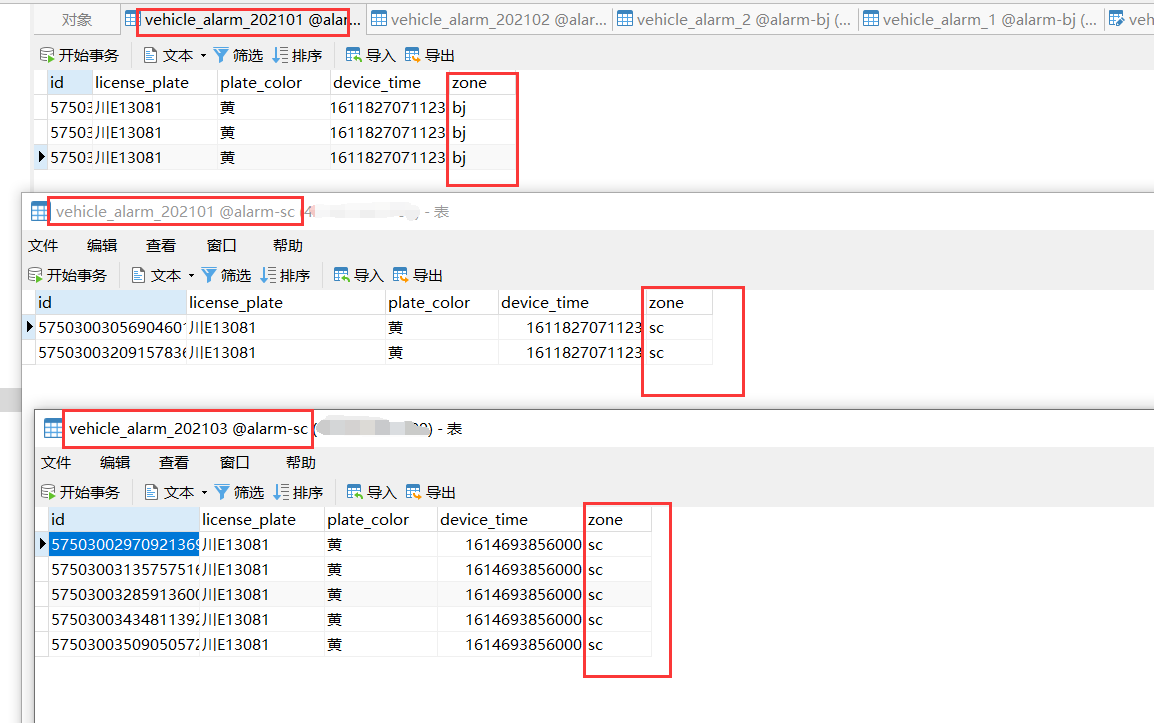
由于我们开启了 SQL 打印,可以看到 sharding-jdbc 对我们的 sql 进行的改写,找到了对应的库与表
将真实 sql 与逻辑 sql 一一打印了出来


@Test
public void testEq() {
LambdaQueryWrapper<VehicleAlarm> wrapper = new QueryWrapper<VehicleAlarm>().lambda();
wrapper.eq(VehicleAlarm::getZone, "bj");
List<VehicleAlarm> vehicleAlarms = vehicleAlarmMapper.selectList(wrapper);
System.out.println(vehicleAlarms);
}
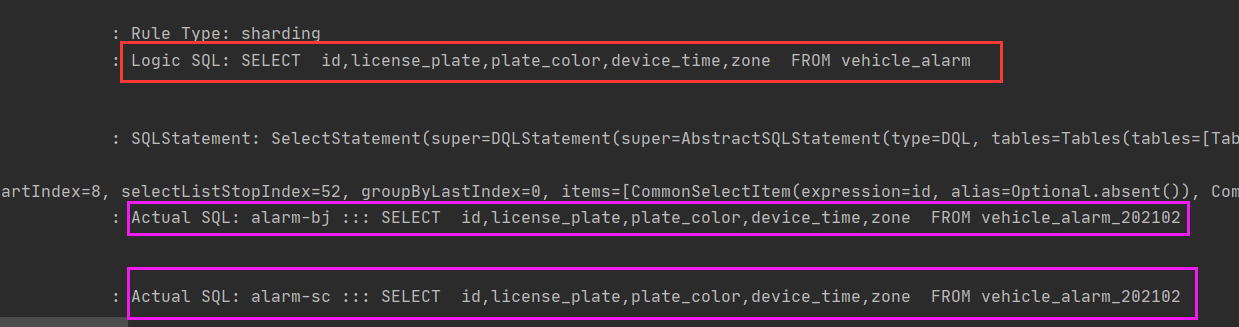
逻辑sql:Logic SQL: SELECT id,license_plate,plate_color,device_time,zone FROM vehicle_alarm WHERE (zone = ? AND device_time = ?)
实际sql:Actual SQL: alarm-bj ::: SELECT id,license_plate,plate_color,device_time,zone FROM vehicle_alarm_202102
WHERE (zone = ? AND device_time = ?) ::: [bj, 1612274617000]
测试范围选择
@Test
public void testTableDbBetween1() {
LambdaQueryWrapper<VehicleAlarm> wrapper = new QueryWrapper<VehicleAlarm>().lambda();
List<String> zoneList = Arrays.asList("bj","sc");
DbSelectUtil.DB_SELECTOR.set(zoneList);
wrapper.between(VehicleAlarm::getZone, "bj","sc")
.eq(VehicleAlarm::getDeviceTime, 1614517065621L);
List<VehicleAlarm> vehicleAlarms = vehicleAlarmMapper.selectList(wrapper);
DbSelectUtil.DB_SELECTOR.remove();
System.out.println(vehicleAlarms);
}
(5)注意事项:
如果您定义了分片策略后,您的逻辑 SQL 操作必须要命中对应的分片策略 例如精准 ,范围等(例如我必须要 EQ device_time,EQ zone,BeTween device_time zone 等等,如果未命中分片算法,则 sharding-jdbc 无法知道您要作用到哪个库与表,会使用默认的逻辑表与库,如过您不存在这样的库与表,则会报错库 或者表不存在的异常)