更新:talkGPT4All 2.0 已经发布,增加了支持的语言模型数量,集成 GPT4All 的方式更加优雅,详情参见这篇文章。
1. 概述
TL;DR:
talkGPT4All 是一个在 PC 本地运行的基于 talkGPT 和 GPT4All 的语音聊天程序,通过 OpenAI Whisper 将输入语音转文本,再将输入文本传给 GPT4All 获取回答文本,最后利用发音程序将文本读出来,构建了完整的语音交互聊天过程。
实际使用效果:
实际上,它只是几个工具的简易组合,没有什么创新的地方(甚至不支持多轮聊天,只支持英文),但 talkGPT4All 有下面几个比较好的特点:
- 所有算法本地运行,不涉及 API 的调用,避免了国内无法访问 OpenAI API 的问题
- CPU 运行,无须 GPU 显卡
- 占内存小,实测 8G 内存就可以跑起来
- 速度还可以,测试 8G Windows 一轮聊天小于 1 分钟, 16G Mac M1 一轮聊天小于 30 秒
- 集成的 AI 还算智能,至少答能对题,回答看起来是符合英语语法的
目前支持平台和验证的情况如下:
- Mac M1,已经验证可用
- Windows,已经验证可用
- Mac Intel,未验证
- Linux,未验证
接下来对为什么造轮子和安装过程进行一步步地说明。如果不想了解细节的话,可以直接跳转到第 3 部分开始上手安装。
2. 为什么造这个轮子
聊天机器人是我比较喜欢的一个应用,机器 + 人类的思维是一个很有意思的场景。另一方面,通过一个智能机器人来练习英语口语,也是一个很实际的应用。
一直以来,想要做一个含有智能的聊天机器人应用都是难度很大的,尤其是智能化的程度,受学术研究进展的制约,没法做到很高。然而近期的 AI LLM 大爆发,让开发一个真正智能的 AI 聊天机器人越来越容易。
最早看到的是基于 whisper.cpp 的 talk.wasm, 一个基于 Whisper+GPT-2 的浏览器对话机器人,实际测试后发现 GPT-2 还不够智能,回答很多时候都答非所问。
然后是在 ChatGPT 出来后,我在想能不能做一个 Whisper + ChatGPT 的智能聊天机器人呢,搜索后发现 whisper.cpp 的讨论区已经有人在讨论这个事情,不过没看到成品。
在 ChatGPT 开放 API 后,有人做了一个 MacOS 上的基于 OpenAI API 的语音聊天机器人 talkGPT,简单好用,唯一的问题是需要借助 OpenAI API,目前国内是不太好访问的。
再然后是 llama.cpp,通过量化和大量工程优化,让原本参数量很大的 LLaMA 模型可以跑在普通的笔记本上(现在甚至支持在 Android 上运行!),但实际测试经过量化后 LLaMA 7B 模型智能程度不太高,有时候会出错,而 更大的 LLaMA 15B 和 30B 在 8GB 内存的 Windows 机器上跑起来就比较难了(最新进展:大小 20GB 的 30B 模型可以在 8G 的系统上运行了,参见这个优化和这里的讨论)。
这周又出现了 gpt4all,基于 LLaMA 7B 模型,采集近 80 万的 GPT-3.5-Turbo 对话数据进行 finetune,效果看起来比 LLaMA 7B 要好。作者发布了他们训练好的经过量化的模型,大小 3.9G,以及可以直接在 PC 上运行的二进制聊天程序,可以直接在各个平台运行。
然后长久以来的 TODO 可以实现了,在缝合了 talkGPT 和 GPT4All 后,就有了 talkGPT4All。简单来说,是把 talkGPT 的 OpenAI API 换成了 GPT4All 提供的本地可以运行的量化模型,也可以说是在 GPT4All 的基础上添加了语音转文本和文本转语音的功能。
那下面我们来看看怎么安装和运行这个缝合怪吧。
3. 构建环境
由于整个程序设计到 Python 代码环境的搭建、Whisper 语音转文本模型的下载、GPT4All 语言模型的下载、GPT4All 聊天程序的下载、文本转语音程序的下载,整体链路略长,下面分步骤分平台分别进行详细说明。
3.1 Python 环境的搭建
在不同平台 Python 代码环境的搭建是一致的。
推荐使用 >= 3.8 的 Python 版本,因为新版本的 Python 有一定的速度提升。低版本可能一些功能不支持。 首先 clone 代码:
git clone https://github.com/vra/talkGPT4All.git
后面假设代码仓库的根目录为<ROOT>来进行命令说明。
基于 Python 自带的 venv 来搭建隔离的环境,并进行依赖安装:
cd <ROOT>
python -m venv talkgpt4all
source talkgpt4all/bin/activate
pip install -U pip
pip install -r requirements.txt
3.2 Whisper 语音转文本模型下载
Whisper 模型在调用时会自动下载,但有时候在命令行下载速度比较慢,我们可以在浏览器中提前下载后放置到对应目录,解决这个问题。 Whisper 的所有模型地址参见这里,我们用的是base.pt,地址是 https://openaipublic.azureedge.net/main/whisper/models/ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e/base.pt,放置的目录是$HOME/.cache/whisper(Windows 上是C:\Users\username\.cache\whisper), 通过浏览器或 wget 下载base.pt到这个目录就行。
3.3 GPT4All 语言模型的下载
语言模型放置目录是<ROOT>/models,根据 GPT4All 文档,下载方式包括
- 链接直接下载
- torrent 下载
- 有些知友评论模型无法下载,我查了作者仓库证书为 MIT,支持模型的分发,因此上传到阿里云盘上,可以在这里下载,下载完后记得将后缀名从. txt 修改为. bin(阿里云盘不支持分享点. bin 格式的文件)
选择其中一种方式,将下载后的模型放置到<ROOT>/models目录下。
3.3 GPT4All 聊天程序下载
GPT4All 的作者打包了多平台的二进制聊天程序,可以下载后直接使用,不用从源码编译 C++ 文件。
聊天程序的放置目录是<ROOT>/bin,不同平台的下载地址如下:
- Mac M1: https://raw.githubusercontent.com/nomic-ai/gpt4all/main/chat/gpt4all-lora-quantized-OSX-m1
- Mac Intel : https://raw.githubusercontent.com/nomic-ai/gpt4all/main/chat/gpt4all-lora-quantized-OSX-Intel
- Linux : https://raw.githubusercontent.com/nomic-ai/gpt4all/main/chat/gpt4all-lora-quantized-linux-x86
- Windows : https://raw.githubusercontent.com/nomic-ai/gpt4all/main/chat/gpt4all-lora-quantized-win64.exe
下载你的平台的文件,放置到<ROOT>/bin。
3.4 文本转语音程序下载
在 Mac 下,自带 say 命令,可以将文本转语音,因此不需要额外安装工具。
在 Linux 下,有 espeak 命令可以来完成文本转语音,但需要额外安装,Ubuntu 下的安装命令为sudo apt install espeak,别的发行版也可以用包管理安装。如果不行的话,尝试下载源码自行编译安装。
Windows 下有一个 say 命令的替代 wsay, 可以在这里下载 wsay.exe,放置到<ROOT>/bin目录下。
4. 使用
安装完成后,进入<ROOT>目录,启用虚拟环境,使用python chat.py --platform <platform>运行程序,<platform>分别是mac-m1, mac-intel, linux, windows。
Mac M1:
python chat.py --platform mac-m1
Mac Intel:
python chat.py --platform mac-intel
Linux:
python chat.py --platform linux
Windows:
python chat.py --platform windows
⚠️注意:目前只测试过 Mac M1 和 Windows,别的平台未测试,如有问题,欢迎提 issue 和 PR 。
在 Mac 上使用效果如下:
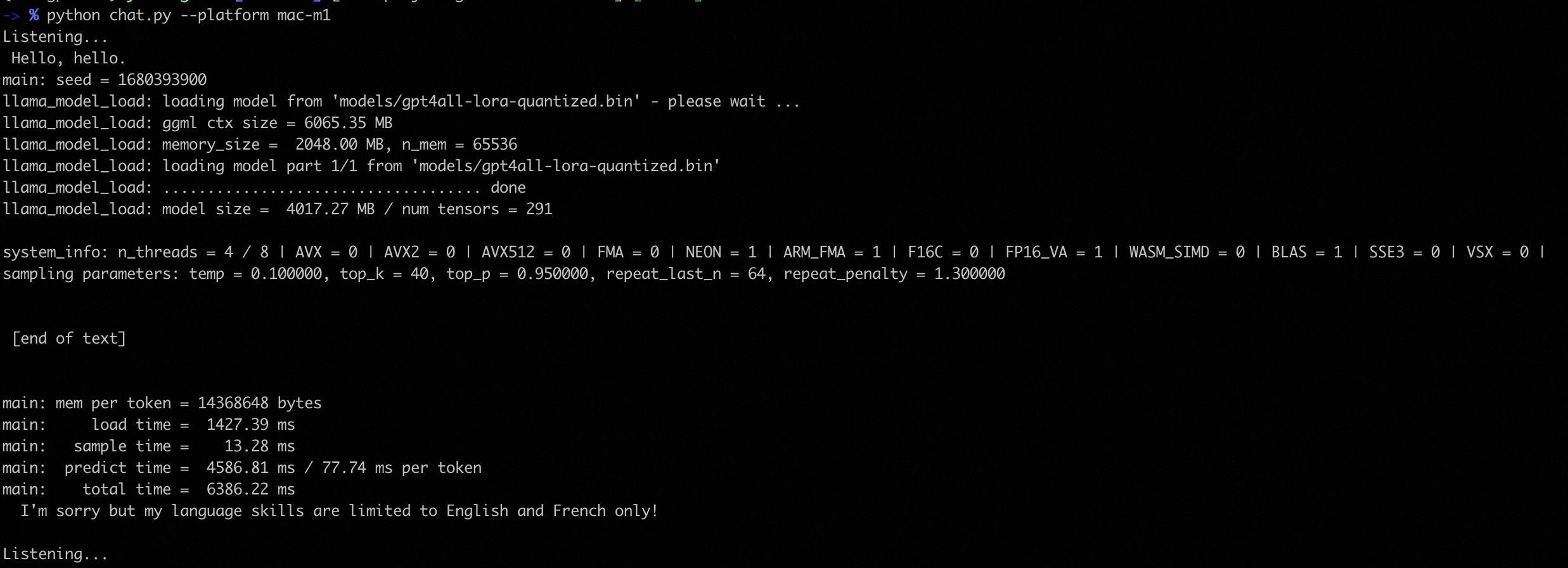
也可以参见本文开头的视频或这里。
5. 后续改进思路
目前实现还是比较粗糙,计划后续会增加下面的功能(按实现难度从低到高排列):
- 验证 Linux,Mac Intel 和 WSL2 下能否正常运行
- 增加多轮对话支持
- 增加中文支持
- 去掉编译好的二进制程序,包含 llama.cpp 源码,自行编译,支持更灵活的使用
- 更多效果更好模型的添加
欢迎基于这个仓库进行修改和代码分发,期待创造出更有新意、更有应用价值的东西~